
tellusboutyourself
[경경데 Week 2] R setup, variables & operations, Basic R grammar | Datatype 본문
카테고리 없음
[경경데 Week 2] R setup, variables & operations, Basic R grammar | Datatype
금서_ 2024. 9. 20. 17:09
2024.09.13.FRI Week 2
중앙대학교 경영경제데이터분석 소프트웨어 _ 김황 교수님
- R produces Two types of files
- xxx.R → script file to save your code
- xxx.RData → console windows to save your data and analysis results
- working directory 설정하는 법
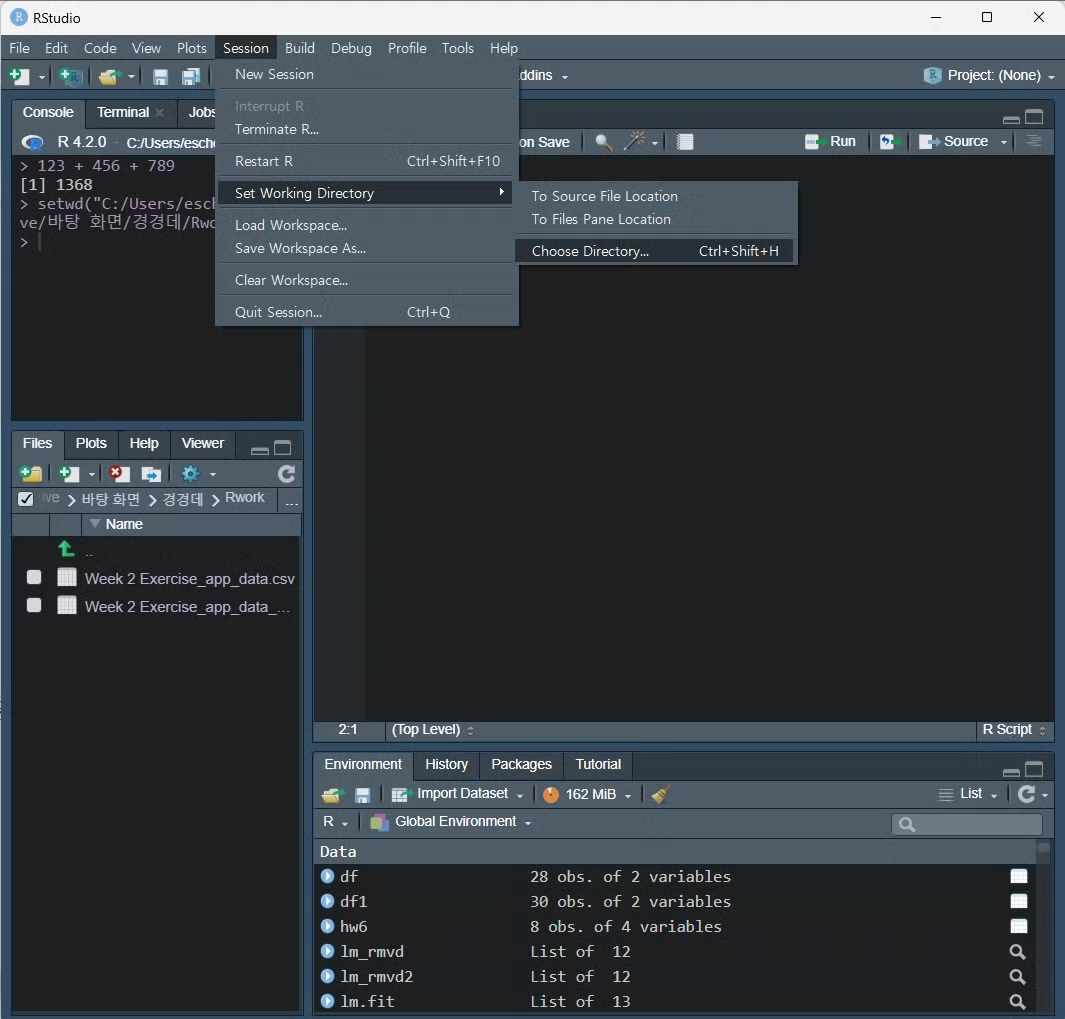
choose directory를 해서 데이터를 넣어둔 파일을 선택할 것.
데이터와 워크스페이스가 같은 폴더 내에 있어야 작업하기 편하다.
- R 파일 저장하기

- RData 파일 저장하기
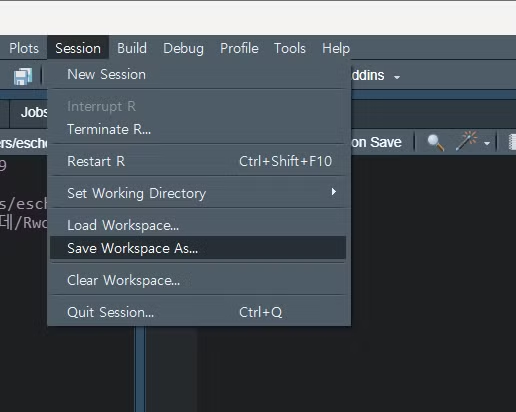
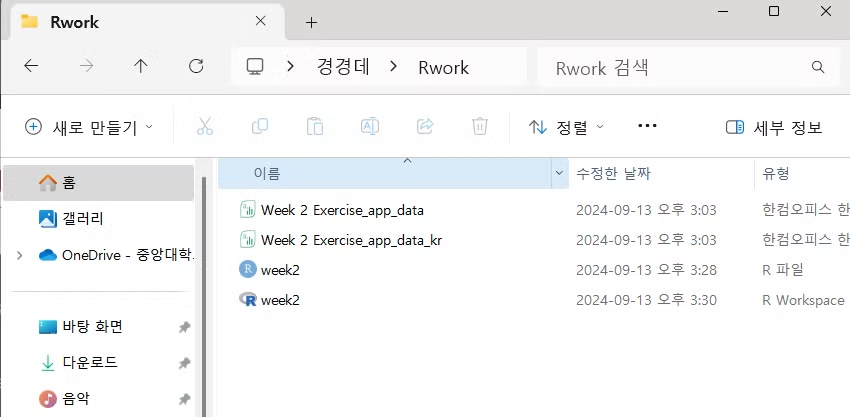
맨 밑의 RData 파일을 연결 프로그램 → rstudio 이렇게 해서 열어서 작업할 것임.
- 코드 입력하는 법
- in the script windows , write code (콘솔창에서도 입력 가능)
- 코드 실행하는 법
- highlight them → click run
- save your script file occasionally !
- (스크립트 창 좌상단 저장 버튼으로)
- create a variable
- x = 3 x <- 3
- 변수에 관해
- x1, x2, A, B, C for variable names
- Not recommended
- make as specific variables names as possible
- e.g., price of product A
- price_A
- Any languages do not allow spaces in variable names
- e.g., price A is not allowed
- price_A is allowed for all languages (R, Python, C++)
- price.A is allowed ONLY in R
- R is case-sensitive like Python, C++, etc.
- You can keep overwriting variables
- Y = 4 X + Y X = 5 X + Y
- DataType
- logical : 2개의 옵션밖에 없는 데이터. t/f 이런 것. (파이썬에서는 앞 글자만 대문자. 그러나 r에서는 모두 대문자로 작성해야 함. TRUE/FALSE 이렇게 . )
- Vector
- want to save 1,2,3,4 into a variable Z
# c를 앞에 꼭 붙여야 한다. > Z = c(1,2,3,4) > Z [1] 1 2 3 4 Z = c(TRUE, FALSE, TRUE) # 큰 따옴표 작은 따옴표 모두 가능하다. Z = c('TOM', 'EMMA', 'JACK') Z = c("TOM", "EMMA", "JACK")- more tricks for vectors
Z1 = c(1:15) Z2 = seq(from=1, to=15) # Z2 = seq(1,15) 로도 표현할 수 있다. Z3 = seq(from=1, to=15, by=2) # Z3 = seq(1,15,2) Z4 = seq(from=1, to=15, length=3) # Z4 = seq(1,15,,3)# 각 변수의 결과 > Z1 [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [15] 15 > Z2 [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 [15] 15 > Z3 [1] 1 3 5 7 9 11 13 15 > Z4 [1] 1 8 15- rep (what to repeat, how many times to repeat)
A1 = c(1,1,1,1,1,1) A2 = rep(1,6) A3 = rep(1:3,6) # same as A = rep(1:3,times=6) A4 = rep(1:3,each=6) A5 = rep(1:3,times=2,each=3) # 전체 부분을 총 2번 반복한다.# 결과 > A1 [1] 1 1 1 1 1 1 > A2 [1] 1 1 1 1 1 1 > A3 [1] 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 > A4 [1] 1 1 1 1 1 1 2 2 2 2 2 2 3 3 3 3 3 3 > A5 [1] 1 1 1 2 2 2 3 3 3 1 1 1 2 2 2 3 3 3- Change variable types
- as.numeric(x) : change tje type of X to numeric
- as.logical(x) : change the type of x to logical
- as.character(x)
- as.factor(x) : change the type of x to factor
- What is factor type?
- 숫자가 정말 수치를 나타내는지 아니면 명시적으로 구분되기 위한 값인지를 r이 구분하지 못할 때가 있다.
- categorical variables
Month = 1,2,3,4,5,6,7,8,9,10,11,12.. # R assigns a numeric type to MOnth variable -> wrong! mm = as.factor(mm) - More about vectors
- can use math operations, +, -, *, /, ….
- can use functions, sqrt, log, …
> A = c(1,2,3) > B = c(4,5,6) > A + B [1] 5 7 9 > B^2 [1] 16 25 36 > sqrt(B) [1] 2.000000 2.236068 2.449490 > mean(B) # AVERAGE in Excel [1] 5 > sd(B) # STDEV in Excel [1] 1 > log(B) # LN in Excel, log in Excel indicates log base 10 [1] 1.386294 1.609438 1.791759 > A = c(1,2,3,4) > B = c(4,5,6) > A+B [1] 5 7 9 8 Warning message: In A + B : longer object length is not a multiple of shorter object length # 객체의 길이가 다르다는 오류가 뜬다. > A = c(1,2,3) > B = c(4,5,6) > A * B [1] 4 10 18 # These are not available in python - Index System
- Access elements in a vector
A = c(1,2,3,4)- want to access the forst element in A
> A[1] # 1 is called INDEX [1] 1 > A[2] [1] 2 > A[1:3] [1] 1 2 3 > A[c(1,3)] [1] 1 3 > A[-2] [1] 1 3 4 # negative index means deleting it. # 2만 제외한다는 뜻 # 파이썬과는 확연히 다름. 파이썬에서는 2만 제외한다는 뜻 - more about factors
- reminder : factor is a categorical variable
- 즉, 문자형으로 지정
A = c("Yes","No","Yes","No")- No matter how many values (obs) in A, each value takes either of “yes” of “no”
- 팩터로 정의된 벡터이기 때문에 범주형 데이털
B = factor(c("Yes","No","Yes","No"))- 결과 비교
첫 번째는 문자형으로 지정되었고, 두 번째는 범주형으로 지정된다.> A [1] "Yes" "No" "Yes" "No" > B [1] Yes No Yes No Levels: No Yes